Кодирование для чайников, ч.1
Содержание:
- Гипносуггестивная терапия
- Почему стоит делать кодировку от алкоголя?
- Свойства звука
- Звуки и их разрядность
- Кодировки стандарта ASCII[править]
- Метод координат
- 2.2 Коды переменной длины
- Стандарты кодирования текста
- Исправляем отображение русских букв в Windows 10
- Способы кодировки
- 2.5.1 Строки и подстроки
- Машинные команды
- Текстовое значение
- Двоичная методика
- Эволюция требований к чистому коду
- Современные способы кодирования данных
- Кодирование и декодирование текстовой информации
Гипносуггестивная терапия
Эта методика включает в себя введение пациента в состояние гипнотического сна, во время которого он становится особенно восприимчивым к убеждению. Когда человек входит в состояние сна, врач производит словесное внушение на выработку спокойного или нейтрального отношения к алкоголю. В результате этого полностью устраняются все причины патологической или даже маниакальной тяги к алкоголю.
Преимущества лечения алкоголизма гипнозом:
-
возможность кодирования пациентов с тяжелыми сопутствующими заболеваниями внутренних органов;
-
этот вид кодирования можно без каких-либо проблем сочетать с медикаментозной терапией;
погружение в гипнотический сон является абсолютно безболезненной процедурой.
Минусы данной методики:
-
существует достаточно большая категория больных, не поддающихся гипнотическому внушению;
-
лечение дает результат только после полного устранения абстинентного синдрома;
-
эффективность лечения напрямую зависит от реального желания излечиться от алкогольной зависимости.
Почему стоит делать кодировку от алкоголя?
Стоит ли делать кодировку от алкоголя?
Кодирование позволяет начать процессы лечения от алкоголизма
Одно из главных требований к началу лечения алкоголизма — прекращения употребления алкоголя. И если пациент не может прекратить пить спиртное своим желанием, своей силой воли, то рекомендуется кодирование как гарантированный способ прекращения употребления алкогольных напитков. Кроме того, после противоалкогольного закодирования у пациента появляется возможность восстановить свое здоровье, наладить семейные отношения и рабочую карьеру.
Кодировка от алкоголя позволяет восстановить свое здоровье
Здоровье у пьющего человека практически всегда будет подорвано. Алкоголь создает на промежуточной стадии окисления в организме сильнейшее токсичное вещество — ацетальдегид . Оно способно значительно подорвать здоровье внутренних органов пьющего алкоголь человека.
Кодировка позволяет избавиться от употребления алкоголя на какое-то время, а значит прекратится воздействие на организм токсином ацетальдегидом и начать «ремонтировать» свое здоровье.
Восстановления полноценного рабочего режима после кодирования
Пьянство значительно мешает работе человека. Он способен пропускать рабочие дни из-за запоев, опаздывать на работу из-за похмельного туманного утра, быть пьяным на рабочем месте. Все это часто не допускает работодатель, и человек теряет свое рабочее место, кадровую перспективу.
В процессе увеличения доз потребления и частоты пьяных посиделок, человек все больше и больше теряет возможность возвращения трезвой нормальной жизни, а значит и возможности полноценно работать и зарабатывать денег для себя и семьи.
Также происходит постепенная деградация личности, так как спирт (этанол) уничтожает часть популяции нейронов в мозгу. С каждой пьянкой нейронов и их связей в голове у пьяницы становится все меньше и меньше.
Кодировка от употребления спиртного позволит восстановить отношения в семье
Семье пьющего человека очень трудно — ведь терпеть пьяного всегда тяжело. Он часто не контролирует ситуацию и свои эмоции, раздражен, и не дает семье и окружающим покоя. Многие сталкивались с такой ситуацией в детстве. У кого-то родственник пьет, и с ним одни проблемы. У кого-то знакомые намучались и не знают как сделать так, чтобы алкоголик прекратил пить навсегда
Кодировка от спиртного позволяет прекратить на достаточно длительное время пьянство, запои, пьяные дебоши и вечерние скандалы на фоне алкоголизма. После окончания кодировки ее можно будет сделать снова.
Поэтому кодировка от алкоголя — это хороший способ прекращения употребления спиртного у больного алкогольной зависимостью.
Свойства звука
Характеристиками звука являются тон, тембр (окраска звука, зависящая от формы колебаний), высота (частота, которая определяется частотой колебаний в секунду) и громкость, зависящая от интенсивности колебаний. Любой реальный звук состоит из смеси гармонических колебаний с фиксированным набором частот. Колебание с самой низкой частотой называют основным тоном, остальные — обертонами. Особую окраску звуку придает тембр — различное количество обертонов, присущее именно этому звуку. Именно по тембру мы можем узнавать голоса близких людей, отличать звучание музыкальных инструментов.
Звуки и их разрядность
C 90-х годов компьютеры работают со звуковой информацией. В каждой вычислительной машине предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Чем больше последний показатель, тем он громче для человеческого восприятия. Чем будет больше частота, тем выше тон.
Современное программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность электроимпульсов. Для шифровки последних явлений используются двоичная форма и аудиоадаптер либо звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс наблюдается при вводе звуков и обратном их преобразовании.
В задачи аудиоадаптера входят:
- измерение амплитуды электрического тока с конкретным периодом;
- данные заносятся в регистр, а затем в оперативную память.
Качество звука определяется следующими понятиями: дискретизация и разрядность. Первый термин связан с количеством измерений входящих сигналов за одну секунду. Показатель измеряется в герцах (Гц). Для одного измерения за секунду характерна частота в 1 Гц. Под разрядностью подразумевается число бит в регистре звуковой платы. Величина определяет точность измерения входящих сигналов.
Чем она выше, тем меньше погрешность отдельных преобразований величины электросигнала в число и обратно. Для разрядности равной 8 получается 256 разных значений. Аудиоадаптер, в котором предусмотрено 16 разрядов, лучше кодирует и воспроизводит звуки, чем 8-разрядный аналог. Чтобы закодировать файл со звуковой информацией, используется числовая двоичная форма.
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Метод координат
Любые данные можно передать с помощью двоичных чисел, в том числе и графические изображение, представляющие собой совокупность точек. Чтобы установить соответствие чисел и точек в бинарном коде, используют метод координат.
Метод координат на плоскости основан на изучении свойств точки в системе координат с горизонтальной осью Ox и вертикальной осью Oy. Точка будет иметь 2 координаты.
Если через начало координат проходит 3 взаимно перпендикулярные оси X, Y и Z, то используется метод координат в пространстве. Положение точки в таком случае определяется тремя координатами.
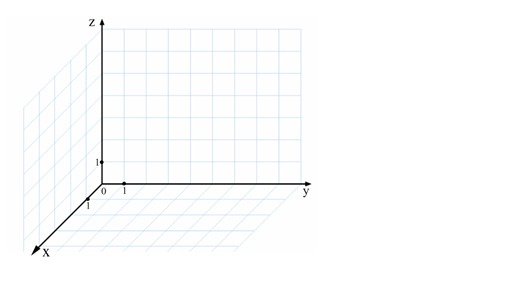 Система координат в пространстве
Система координат в пространстве
2.2 Коды переменной длины
Воспользуемся той же строкой и таблицей и попробуем данные закодировать иначе. Уберём блоки фиксированного размера и представим данные исходя из их частоты использования — чем чаще данные используются, чем меньше бит мы будем использовать. У нас получится вторая таблица:
|
Символ |
Количество |
Переменный код, бит |
|---|---|---|
|
ПРОБЕЛ |
18 |
|
|
Р |
12 |
1 |
|
К |
11 |
00 |
|
Е |
11 |
01 |
|
У |
9 |
10 |
|
А |
8 |
11 |
|
Г |
4 |
000 |
|
В |
3 |
001 |
|
Ч |
2 |
010 |
|
Л |
2 |
011 |
|
И |
2 |
100 |
|
З |
2 |
101 |
|
Д |
1 |
110 |
|
Х |
1 |
111 |
|
С |
1 |
0000 |
|
Т |
1 |
0001 |
|
Ц |
1 |
0010 |
|
Н |
1 |
0011 |
|
П |
1 |
0100 |
Для подсчёта длины закодированного сообщения мы должны сложить все произведения количества символов на длины кодов в битах и тогда получим 179 бит.
Но такой способ, хоть и позволил прилично сэкономить память, но не будет работать, потому что невозможно его раскодировать. Мы не сможем в такой ситуации определить, что означает код «111», это может быть «РРР», «РА», «АР» или «Х».
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.
ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название — American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара — «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.
Исправляем отображение русских букв в Windows 10
Существует два способа решения рассматриваемой проблемы. Связаны они с редактированием настроек системы или определенных файлов. Они отличаются по сложности и эффективности, поэтому мы начнем с легкого. Если первый вариант не принесет никакого результата, переходите ко второму и внимательно следуйте описанным там инструкциям.
Способ 1: Изменение языка системы
В первую очередь хотелось бы отметить такую настройку как «Региональные стандарты». В зависимости от его состояния и производится дальнейшее отображение текста во многих системных и сторонних программах. Редактировать его под русский язык можно следующим образом:
- Откройте меню «Пуск» и в строке поиска напечатайте «Панель управления». Кликните на отобразившийся результат, чтобы перейти к этому приложению.
Среди присутствующих элементов отыщите «Региональные стандарты» и нажмите левой кнопкой мыши на этот значок.
Появится новое меню с несколькими вкладками. В данном случае вас интересует «Дополнительно», где нужно кликнуть на кнопку «Изменить язык системы…».
Корректировки вступят в силу только после перезагрузки ПК, о чем вы и будете уведомлены при выходе из меню настроек.
Дождитесь перезапуска компьютера и проверьте, получилось ли исправить проблему с русскими буквами. Если нет, переходите к следующему, более сложному варианту решения этой задачи.
Способ 2: Редактирование кодовой страницы
Кодовые страницы выполняют функцию сопоставления символов с байтами. Существует множество разновидностей таких таблиц, каждая из которых работает с определенным языком. Часто причиной появления кракозябров является именно неправильно выбранная страница. Далее мы расскажем, как править значения в редакторе реестра.
- Нажатием на комбинацию клавиш Win + R запустите приложение «Выполнить», в строке напечатайте regedit и кликните на «ОК».
- В окне редактирования реестра находится множество директорий и параметров. Все они структурированы, а необходимая вам папка расположена по следующему пути:
Выберите «CodePage» и опуститесь в самый низ, чтобы отыскать там имя «ACP». В столбце «Значение» вы увидите четыре цифры, в случае когда там выставлено не 1251, дважды кликните ЛКМ на строке.
Двойное нажатие левой кнопкой мыши открывает окно изменения строковой настройки, где и требуется выставить значение 1251 .
Если же значение и так уже является 1251, следует провести немного другие действия:
- В этой же папке «CodePage» поднимитесь вверх по списку и отыщите строковый параметр с названием «1252» Справа вы увидите, что его значение имеет вид с_1252.nls. Его нужно исправить, поставив вместо последней двойки единицу. Дважды кликните на строке.
Откроется окно редактирования, в котором и выполните требуемую манипуляцию.
После завершения работы с редактором реестра обязательно перезагрузите ПК, чтобы все корректировки вступили в силу.
Подмена кодовой страницы
Некоторые пользователи не хотят править реестр по определенным причинам либо же считают эту задачу слишком сложной. Альтернативным вариантом изменения кодовой страницы является ее ручная подмена. Производится она буквально в несколько действий:
- Откройте «Этот компьютер» и перейдите по пути C:\Windows\System32 , отыщите в папке файл С_1252.NLS, кликните на нем правой кнопкой мыши и выберите «Свойства».
Переместитесь во вкладку «Безопасность» и найдите кнопку «Дополнительно».
Вам нужно установить имя владельца, для этого кликните на соответствующую ссылку вверху.
В пустом поле впишите имя активного пользователя, обладающего правами администратора, после чего нажмите на «ОК».
Вы снова попадете во вкладку «Безопасность», где требуется откорректировать параметры доступа администраторов.
Выделите ЛКМ строку «Администраторы» и предоставьте им полный доступ, установив галочку напротив соответствующего пункта. По завершении не забудьте применить изменения.
Вернитесь в открытую ранее директорию и переименуйте отредактированный файл, поменяв его расширение с NLS, например, на TXT. Далее с зажатым CTRL потяните элемент «C_1251.NLS» вверх для создания его копии.
Нажмите на созданной копии правой кнопкой мыши и переименуйте объект в C_1252.NLS.
Вот таким нехитрым образом происходит подмена кодовых страниц. Осталось только перезапустить ПК и убедиться в том, что метод оказался эффективным.
Как видите, исправлению ошибки с отображением русского текста в операционной системе Windows 10 способствуют два достаточно легких метода. Выше вы были ознакомлены с каждым. Надеемся, предоставленное нами руководство помогло справиться с этой неполадкой.
Способы кодировки
Проанализируем разнообразные виды информации и особенности ее кодирования.
По принципу представления все информационные сведения можно классифицировать на следующие группы:
- графическая;
- аудиоинформация (звуковая);
- символьная (текстовая);
- числовая;
- видеоинформация.
Способы кодирования информации обусловлены поставленными целями, а также имеющимися возможностями,методами ее дальнейшей обработки и сохранения. Одинаковые сообщения могут отображаться в виде картинок и условных знаков (графический способ), чисел (числовой способ) или символов (символьный способ).
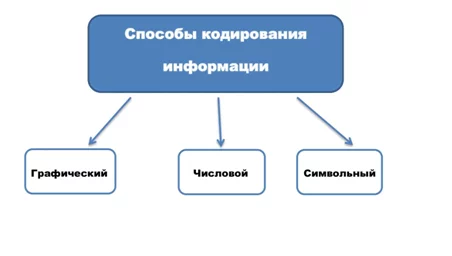
Соответственно происходит и классификация информации по способу кодирования:
- символьные сообщения включают знаки дорожного движения, сигналы светофора и т.д.;
- текстовые данные – это книги, нотные записи, различные документы;
- всевозможные изображения (фотографии, схемы, рисунки) представляют все многообразие графической информации.
Чтобы расшифровать сообщение, отображаемое в выбранной системе кодирования информации, необходимо осуществить декодирование – процесс восстановления до исходного материала. Для успешного осуществления расшифровки необходимо знать вид кода и методы шифрования.
Самыми распространенными видами кодировок информации являются следующие:
- преобразование текста;
- графическая кодировка;
- кодирование числовых данных;
- перевод звука в бинарную последовательность чисел;
- видеокодирование.
Различают такие методы кодирования информации как:
- метод замены (подстановки) – знаки первоначального сообщения заменяются на соответствующие символы выбранного кодового алгоритма;
- метод перестановки – символы оригинального текста меняются местами по определенной схеме;
- метод гаммирования – к исходным обозначениям добавляется случайная последовательность других знаков.
2.5.1 Строки и подстроки
До сих пор мы кодировали данные, рассматривая их как совокупность отдельных символов. Сейчас мы попробуем кодировать целыми словами.
Напомню нашу строку: «ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП».
Составим таблицу повторов слов:
|
Слово |
Количество |
|---|---|
|
ПРОБЕЛ |
18 |
|
ГРЕКА |
3 |
|
В |
2 |
|
РАК |
2 |
|
РЕКУ |
2 |
|
РУКУ |
2 |
|
ВИДИТ |
1 |
|
ГРЕКУ |
1 |
|
ЕХАЛ |
1 |
|
ЗА |
1 |
|
РЕЧКЕ |
1 |
|
СУНУЛ |
1 |
|
ЦАП |
1 |
|
ЧЕРЕЗ |
1 |
Для кодирования нам нужно придумать концепцию, например — мы создаём словарь и каждому слову присваиваем индекс, пробелы игнорируем и не кодируем, но считаем, что каждое слово разделяется именно символом пробела.
Сначала формируем словарь:
|
Слово |
Количество |
Индекс |
|---|---|---|
|
ГРЕКА |
3 |
|
|
В |
2 |
1 |
|
РАК |
2 |
2 |
|
РЕКУ |
2 |
3 |
|
РУКУ |
2 |
4 |
|
ВИДИТ |
1 |
5 |
|
ГРЕКУ |
1 |
6 |
|
ЕХАЛ |
1 |
7 |
|
ЗА |
1 |
8 |
|
РЕЧКЕ |
1 |
9 |
|
СУНУЛ |
1 |
10 |
|
ЦАП |
1 |
11 |
|
ЧЕРЕЗ |
1 |
12 |
Таким образом наша строка кодируется в последовательность:
7, 0, 12, 3, 5, 0, 1, 9, 2, 10, 0, 4, 1, 3, 2, 8, 4, 6, 11
Это подготовительный этап, а вот то, как именно нам кодировать словарь и данные уже после подготовительного кодирования — процесс творческий. Мы пока останемся в рамках уже известных нам способов и начнём с блочного кодирования.
Индексы записываем в виде блоков по 4 бита (так можно представить индексы от 0 до 15), таких цепочек у нас будет две, одна для закодированного сообщения, а вторая для соответствия индексу и слову. Сами слова будем кодировать кодами Хаффмана, только нам еще придется задать разделитель записей в словаре, можно, например, указывать длину слова блоком, самое длинное слово у нас в 5 символов, для этого хватит 3 бита, но так же мы можем использовать код пробела, который состоит из двух бит — так и поступим. В итоге мы получаем схему хранения словаря:
|
Индекс / биты |
Слово / биты |
Конец слова / биты |
|---|---|---|
|
0 / 4 |
ГРЕКА / 18 |
ПРОБЕЛ / 2 |
|
1 / 4 |
В / 5 |
ПРОБЕЛ / 2 |
|
2 / 4 |
РАК / 10 |
ПРОБЕЛ / 2 |
|
3 / 4 |
РЕКУ / 12 |
ПРОБЕЛ / 2 |
|
4 / 4 |
РУКУ / 12 |
ПРОБЕЛ / 2 |
|
5 / 4 |
ВИДИТ / 31 |
ПРОБЕЛ / 2 |
|
6 / 4 |
ГРЕКУ / 17 |
ПРОБЕЛ / 2 |
|
7 / 4 |
ЕХАЛ / 20 |
ПРОБЕЛ / 2 |
|
8 / 4 |
ЗА / 10 |
ПРОБЕЛ / 2 |
|
9 / 4 |
РЕЧКЕ / 18 |
ПРОБЕЛ / 2 |
|
10 / 4 |
СУНУЛ / 26 |
ПРОБЕЛ / 2 |
|
11 / 4 |
ЦАП / 17 |
ПРОБЕЛ / 2 |
|
12 / 4 |
ЧЕРЕЗ / 21 |
ПРОБЕЛ / 2 |
|
7 |
12 |
3 |
5 |
1 |
9 |
2 |
10 |
4 |
1 |
3 |
2 |
8 |
4 |
6 |
11 |
и само сообщение по 4 бита на код.
Считаем всё вместе и получаем 371 бит. При этом само сообщение у нас было закодировано в 19*4=76 бит. Но нам всё еще требуется сохранять соответствие кода Хаффмана и символа, как и во всех предыдущих случаях.
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК). Они содержат в себе некоторую информацию:
- Местонахождение операнд.
- Хранилище для результатов операций.
- Выбор следующей команды.
У каждого процессора МК со стандартным форматом и строгой фиксированной длиной сама команда состоит из адреса и кода операции. Последний показатель описывает действия процессора. По адресной части определяется, где была произведена операция. С учётом её структуры она классифицируется на моно- и мультиадресные части. Длина кода зависит от числа действий, которые входят в систему компьютера.
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Двоичная методика
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. В процессе хранения, обработки и передачи информации в компьютере используется особая двоичная система кодирования, алфавит которой состоит всего из двух знаков «0» и «1». Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Связано это с тем, что в цифровой электронике удобнее всего представлять информацию в виде последовательности электрических импульсов: техническое устройство, безошибочно различающее 2 разных состояния сигнала, оказалось проще создать, чем то, которое бы безошибочно различало 5 или 10 различных состояний. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид. Такое кодирование информации принято называть двоичным, на его основе работают все окружающие нас компьютеры, смартфоны и т.п.
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит {0,1};
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Эволюция требований к чистому коду
Требования к коду менялись со временем. Очевидно, что в 80х годах компьютеры были менее производительны чем сейчас и огромный упор делался на эффективность программ. Рост производительности привел к появлению новых синтаксических конструкций, подходов к программированию и языкам. Так например, использование кодов ошибок вместо исключений в настоящее время считается дурным тоном, однако на заре компьютерной эры исключений просто не существовало.
Однако, изменение требований связано не только с ростом производительности — например, ограничение на ширину и высоту кода стали неактуальны с распространением мониторов с высоким разрешением. На старых мониторах строки, длина которых была более 80 символов, приходилось перематывать — это сильно осложняло чтение кода. Помимо ограничения на ширину, существовало также ограничение высоты функций — очень удобно если функция целиком умещается на один экран монитора. Сейчас эти требования не исчезли совсем, но стали более мягкими — писать весь код в одну строку не стоит.
Выработаны архитектурные конструкции, правильное использование которых упрощает проектирование, восприятие и сопровождение программ — шаблоны проектирования. Шаблоны имеют широкое распространение и хорошо описаны в литературе — если программист, читая исходный код увидит слово Factory, то он заранее знает чего ждать от такого кода. Для каждого шаблона проанализированы сильные и слабые стороны, поэтому их использование предпочтительнее велосипедостроения.
Наконец, изменились средства разработки программ — появились системы контроля версий, удобные инструменты тестирования, системы отслеживания ошибок, управления задачами и многое другое. Весь этот инструментарий оказался интегрирован в удобные среды разработки.
Независимо от того, какой язык программирования вы используете, хороший код должен обладать следующими характеристиками:
- не должен мешать программисту вносить изменения;
- должен легко тестироваться;
- должны использоваться, по возможности, стандартные решения.
Современные способы кодирования данных
Для перевода информации в код могут быть использованы разные способы и алгоритмы кодирования.
Использование каждого из методов зависит от среды, цели и условий создания кода.
С разными алгоритмами кодирования мы сталкиваемся в повседневной жизни:
- Для записи разговорной речи в режиме реального времени используется стенография;
- Для написания и отправки письма жителю другой страны используем язык получателя;
- Для набора русского текста на англоязычной клавиатуре используем транслит. К примеру, «Привет»>«Privet» и так далее.
вернуться к меню
Это интересно: Код ошибки 0x800705b4 на windows: как исправить
Кодирование и декодирование текстовой информации
При нажатии на клавиатурную клавишу компьютер получает сигнал в виде двоичного числа, расшифровку которого можно найти в кодовой таблице – внутреннем представлении знаков в ПК. Стандартом во всем мире считают таблицу ASCII.
Однако мало знать, что такое кодирование и декодирование, необходимо еще понимать, как располагаются данные в компьютере. К примеру, для хранения одного символа двоичного кода электронно-вычислительная машина выделяет 1 байт, то есть 8 бит. Эта ячейка может принимать только два значения: 0 и 1. Получается, что один байт позволяет зашифровать 256 разных символов, ведь именно такое количество комбинаций можно составить. Эти сочетания и являются ключевой частью таблицы ASCII. К примеру, буква S кодируется как 01010011. Когда вы нажимаете ее на клавиатуре, происходит кодирование и декодирование данных, и мы получаем ожидаемый результат на экране.
Половина таблицы стандартов ASCII содержит коды цифр, управляющих символов и латинских букв. Другая ее часть заполняется национальными знаками, псевдографическими знаками и символами, которые не имеют отношения к математике. Совершенно ясно, что в различных странах эта часть таблицы будет отличаться. Цифры при вводе также преобразовываются в двоичную систему вычисления согласно стандартной сводке.





